 Brian Guayante
Brian Guayante


This post was originally published on Stanford Legal Design Lab's A Better Legal Internet.
In the past decade, an average of around twelve million civil cases per year were filed in state courts in the United States. Many of the individuals involved in civil cases, such as eviction proceedings, do not regularly interact with the justice system and are unaware of the resources available to them. Parties responding to a matter also may not know the location of courts in which they have business or rules that may restrict their ability to attend legal proceedings in person.
As a result, there is a real need for tools and resources to provide accurate and easy to access court information to the public litigants. Roughly 60% of all web traffic originated from a search results page in 2019, suggesting that "search" is a place to meet individuals looking for information about courts where they already are. Search engine providers like Google already have tools, guidelines, and standards to make information more easily surfaced in results pages. In these ways, search engine providers present a valuable opportunity to leverage the existing data infrastructure to make court information easier for the public to find.
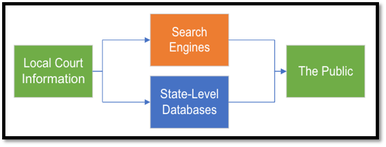
The Turnout partnered with court administrators, technologists, and organizations working to expand the public's access to legal aid and the courts, including the Stanford Legal Design Lab and the National Center for State Courts, to develop a data standard that will make court information easier to find on the internet. Inspired by the Stanford Legal Design Lab's efforts to create a standard taxonomy for legal terms on the web and built on Schema.org, the standards proposed by Google, Microsoft, Yandex, and Yahoo to make data on the web more easily readable by their search engines, The Turnout created a new, comprehensive data standard intended to help local courthouses make information more accessible to the public.
The Court Data Standard leverages the vocabulary provided by Schema.org and SEO guidelines published by Google to improve the quality of search results. Information provided by courthouse administrators, such as a courthouse's location, is stored in a file and hosted on a court's website. Search engines crawling the web are then able to identify that information and increase its visibility in search results. Using the Court Data Standard requires only that individual courthouses make the information files available on their websites and that state-level officials store them.
States like Illinois and California developed "Find My Court" services that allow the public to locate nearby courthouses and view information about them. To support adoption of the Court Data Standard, The Turnout created tools to assist state-level administrators in collecting and aggregating this data for use in their own public-facing court information tools. As a result of adopting the Court Data Standard tools, more courts can develop better data standards and infrastructure for sharing court information online. The process of identifying, collecting, publishing, and replicating quality information readily available to the public on court websites is ready to be extended to other states.